





פייתון הפכה לשפה המרכזית עבור AI ולמידת מכונה – בזכות הפשטות שלה והמערכת האקולוגית העשירה של ספריות.
Pandas – ניתוח ועיבוד נתונים
Pandas מספקת מבנים ברמה גבוהה (DataFrame, Series) לעבודה נוחה עם נתונים טבלאיים ומובנים.
מתי להשתמש ב־Pandas?
כשיש לכם נתונים טבלאיים (כמו קבצי CSV, נתוני מסד) או סדרות זמן – Pandas הוא הכלי הראשון שכדאי לפנות אליו.
עבור עיבוד ברמת איברים (element-wise), NumPy מהיר יותר, אך Pandas נוח יותר כשיש שילוב של סוגי נתונים ותוויות.
scikit-learn – למידת מכונה בקלות
scikit-learn (או בקצרה sklearn) היא ספרייה פופולרית ללמידת מכונה קלאסית – לא למידה עמוקה.
כוללת אלגוריתמים כמו רגרסיה, סיווג, אשכולות, הפחתת מימדים, ועוד.
תכונות מרכזיות
- API עקבי: כל אלגוריתם הוא "אומדן" (Estimator) עם .fit(X, y) ו־.predict(X)
- תומך בקלט מסוג NumPy או Pandas
- Pipelines: שילוב של קדם-עיבוד ואלגוריתם במבנה אחד
- חיפוש פרמטרים: GridSearchCV עם קרוס-ולידציה
דוגמה
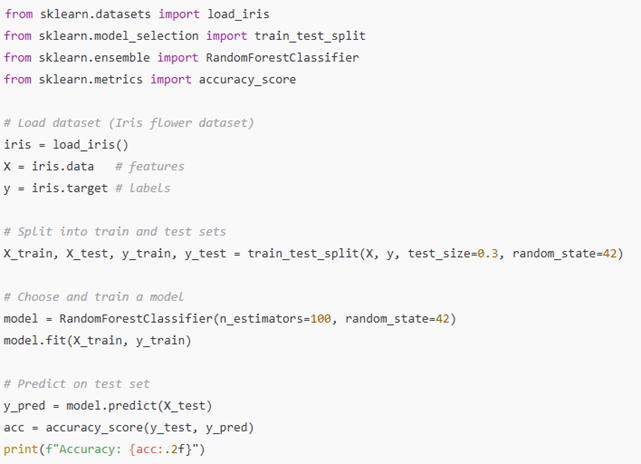
scikit-learn
הוא הבחירה הנכונה ללמידת מכונה קלאסית כאשר נדרש פתרון מהיר, פשוט ואמין לבעיות כמו סיווג, רגרסיה או אשכולות.
הוא לא מיועד לרשתות נוירונים עמוקות – שם משתמשים ב־TensorFlow או PyTorch.




