






מבוא לבינה מלאכותית AI
המסע שלך מתחיל בחקירה של מושגי הליבה והעקרונות שעליהם מבוססת בינה מלאכותית, ומבט כולל על שירותי Microsoft Azure שבהם באפשרותך להשתמש כדי לפתח פתרונות AI:
- הגדרת בינה מלאכותית
- הבנת מונחים הקשורים לבינה מלאכותית
- הבנת שיקולים עבור מהנדסי AI
- הבנת שיקולים עבור בינה מלאכותית אחראית
- הבנת היכולות של למידת מכונה של Azure
- הבנת היכולות של השירותים הקוגניטיביים של Azure
- הבנת היכולות של שירות הבוטים של Azure
- הבנת היכולות של החיפוש הקוגניטיבי של Azure
הגדרת בינה מלאכותית
בינה מלאכותית (AI) נפוצה יותר ויותר ביישומי התוכנה שבהם אנו משתמשים מדי יום; כולל עוזרים דיגיטליים בבתים ובטלפונים הסלולריים שלנו, טכנולוגיית רכב בכלי הרכב שלוקחים אותנו לעבודה, ויישומי פרודוקטיביות חכמים שעוזרים לנו לבצע את עבודתנו כשאנחנו מגיעים לשם.
אז מהי בעצם בינה מלאכותית?
ישנן הגדרות רבות; חלקם טכניים, חלקם פילוסופיים; אך באופן כללי, אנו נוטים לחשוב על בינה מלאכותית כתוכנה המציגה יכולת אחת או יותר דמוית אדם, כפי שמוצג בטבלה הבאה:
 תפיסה חזותית – היכולת להשתמש ביכולות ראייה ממוחשבת כדי לקבל, לפרש ולעבד קלט מתמונות, זרמי וידאו ומצלמות חיות.
תפיסה חזותית – היכולת להשתמש ביכולות ראייה ממוחשבת כדי לקבל, לפרש ולעבד קלט מתמונות, זרמי וידאו ומצלמות חיות.
 ניתוח טקסט – היכולת להשתמש בעיבוד שפה טבעית (NLP) לא רק כדי "לקרוא", אלא גם לחלץ משמעות סמנטית מנתונים מבוססי טקסט.
ניתוח טקסט – היכולת להשתמש בעיבוד שפה טבעית (NLP) לא רק כדי "לקרוא", אלא גם לחלץ משמעות סמנטית מנתונים מבוססי טקסט.

דיבור – היכולת לזהות דיבור כקלט ולסנתז פלט מדובר. השילוב של יכולות הדיבור יחד עם היכולת ליישם ניתוח NLP של טקסט מאפשר צורה של אינטראקציה בין אדם למחשוב שזכתה לכינוי AIs שיחה, שבה משתמשים יכולים לקיים אינטראקציה עם סוכני AI (המכונים בדרך כלל בוטים) באופן דומה מאוד עם אדם אחר.
 קבלת החלטות – היכולת להשתמש בניסיון העבר ובמתאמים שנלמדו כדי להעריך מצבים ולנקוט בפעולות מתאימות. לדוגמה, זיהוי חריגות בקריאות חיישנים ונקיטת פעולה אוטומטית למניעת כשל או נזק למערכת.
קבלת החלטות – היכולת להשתמש בניסיון העבר ובמתאמים שנלמדו כדי להעריך מצבים ולנקוט בפעולות מתאימות. לדוגמה, זיהוי חריגות בקריאות חיישנים ונקיטת פעולה אוטומטית למניעת כשל או נזק למערכת.
יכולות מסוג זה נמצאות יותר ויותר בהישג ידם של יישומי תוכנה יומיומיים, מה שעוזר להפוך אותן לאינטואיטיביות ושימושיות יותר במגוון רחב של תרחישים שהיו קיימים בעבר רק בתחומי המדע הבדיוני.
הבנת מונחים הקשורים לבינה מלאכותית
ישנם מספר מונחים שאנשים משתמשים בהם כאשר מדברים על בינה מלאכותית, ולכן כדאי שיהיו הגדרות ברורות לכל אחד מהם.
מדעי הנתונים
מדעי הנתונים היא דיסציפלינה המתמקדת בעיבוד וניתוח של נתונים; שימוש בטכניקות סטטיסטיות כדי לחשוף ולהמחיש קשרים ודפוסים בנתונים, והגדרת מודלים ניסיוניים המסייעים לחקור דפוסים אלה.
לדוגמה, מדען נתונים עשוי לאסוף דגימות של נתונים על אוכלוסיית המין בסכנת הכחדה באזור גיאוגרפי, ולשלב אותם עם נתונים על רמות התיעוש והדמוגרפיה הכלכלית באותו אזור. לאחר מכן ניתן לנתח את הנתונים, תוך שימוש בטכניקות סטטיסטיות כדי לבצע אקסטרפולציה מהדגימות כדי להבין מגמות וקשרים בין פעילויות אנושיות לחיות בר, ולבחון השערות באמצעות מודלים שמראים את ההשפעה הסבירה של פעילות אנושית על אוכלוסיית חיות הבר. בכך, מדעני הנתונים עשויים לסייע בקביעת מדיניות אופטימלית המאזנת בין הצורך ברווחה כלכלית לאוכלוסייה האנושית לבין הצורך בשימור חיות הבר הנמצאות בסכנת הכחדה.
למידת מכונה
למידת מכונה היא תת-קבוצה של מדעי הנתונים העוסקת באימון ואימות של מודלים חזויים. בדרך כלל, מדען נתונים מכין את הנתונים ולאחר מכן משתמש בהם כדי לאמן מודל המבוסס על אלגוריתם המנצל את קשרי הגומלין בין התכונות בנתונים כדי לחזות ערכים עבור תוויות לא ידועות.
לדוגמה, מדען נתונים עשוי להשתמש בנתונים שהוא אסף כדי לאמן מודל המנבא את הגידול השנתי או הירידה באוכלוסייה של מין בהתבסס על גורמים כגון מספר אתרי הקינון שנצפו, שטח האדמה המוגדר כמוגן, האוכלוסייה האנושית באזור המקומי, נפח התנועה היומי בכבישים מקומיים, וכן הלאה. מודל חיזוי זה יכול לשמש ככלי להערכת תוכניות לדיור, תשתיות ופיתוח תעשייתי באזור המקומי ולהעריך את השפעתן הצפויה על חיות הבר המקומיות.
בינה מלאכותית
בינה מלאכותית בדרך כלל (אך לא תמיד) מתבססת על למידת מכונה כדי ליצור תוכנה המחקה מאפיין אחד או יותר של האינטליגנציה האנושית.
לדוגמה, איזון בין הצורך בשימור חיות בר לבין פיתוח כלכלי מחייב ניטור מדויק של אוכלוסיית המינים בסכנת הכחדה המוגנת. זה לא יכול להיות ריאלי להסתמך על מומחים אנושיים שיכולים לזהות באופן חיובי את החיה המדוברת, או לפקח על שטח גדול על פני פרק זמן מספיק כדי לקבל ספירה מדויקת. ואכן, נוכחותם של משקיפים אנושיים עשויה להרתיע בעלי חיים ולמנוע את גילוים. במקרה זה, מודל חיזוי יכול להיות מאומן לנתח נתוני תמונה שצולמו על ידי מצלמות המופעלות על ידי תנועה במקומות מרוחקים, ולחזות אם תמונה מכילה תצפית של החיה. לאחר מכן ניתן יהיה להשתמש במודל ביישום תוכנה המגיב לזיהוי אוטומטי של בעלי חיים כדי לעקוב אחר תצפיות של בעלי חיים על פני שטח גיאוגרפי גדול, תוך זיהוי אזורים עם אוכלוסיות בעלי חיים צפופות שעשויים להיות מועמדים למעמד מוגן.
הבנת שיקולי AI
יותר ויותר פתרונות תוכנה כוללים תכונות AI; כך שמהנדסי תוכנה צריכים לדעת כיצד לשלב יכולות AI ביישומים ובשירותים שלהם.
ההתקדמות שנעשתה בלמידת מכונה, יחד עם הזמינות המוגברת של כמויות גדולות של נתונים ומחשוב רב עוצמה שעליו ניתן לעבד אותם ולאמן מודלים חזויים, הובילו לזמינות של שירותי תוכנה ארוזים מראש המתמצתים יכולות AI. מהנדסי תוכנה יכולים לנצל שירותים אלה כדי ליצור יישומים וסוכנים המשתמשים בפונקציונליות הבינה המלאכותית הבסיסית, ולהשתמש בהם כאבני בניין ליצירת פתרונות חכמים.
משמעות הדבר היא שמהנדסי תוכנה יכולים ליישם את הכישורים הקיימים שלהם בתכנות, בדיקות, עבודה עם מערכות בקרת מקור ויישומי אריזה לפריסה, מבלי להפוך למדעני נתונים או למומחי למידת מכונה.
עם זאת, כדי לנצל באופן מלא את ההזדמנויות של בינה מלאכותית, מהנדסי תוכנה דורשים לפחות הבנה מושגית של עקרונות הליבה של בינה מלאכותית ולמידת מכונה.
הדרכת מודלים והסקה
מערכות AI רבות מסתמכות על מודלים חזויים שיש לאמן באמצעות נתונים לדוגמה. תהליך האימון מנתח את הנתונים וקובע קשרים בין התכונות בנתונים (ערכי הנתונים שבדרך כלל יהיו נוכחים בתצפיות חדשות) לבין התווית (הערך שהמודל מאומן לחזות).
לאחר אימון המודל, באפשרותך לשלוח נתונים חדשים הכוללים ערכי תכונות ידועים ולבקש מהמודל לחזות את התווית הסבירה ביותר. שימוש במודל לביצוע תחזיות מכונה הסקה.
רבים מהשירותים והמסגרות שמהנדסי תוכנה יכולים להשתמש בהם כדי לבנות פתרונות התומכים בבינה מלאכותית דורשים תהליך פיתוח הכולל אימון של מודל מנתונים קיימים לפני שניתן להשתמש בו כדי להסיק ערכים חדשים ביישום.
ציוני הסתברות וביטחון
מודל למידת מכונה מאומן היטב יכול להיות מדויק, אך אף מודל חיזוי אינו ניתן לערעור. התחזיות של מודלים של למידת מכונה מבוססות על הסתברות, ובעוד שמהנדסי תוכנה אינם דורשים הבנה מתמטית עמוקה של תורת ההסתברות, חשוב להבין שתחזיות משקפות סבירות סטטיסטית, ולא אמת מוחלטת. ברוב המקרים, לתחזיות יש ציון ביטחון משויך המשקף את ההסתברות שבה מתבצעת החיזוי. מפתחי תוכנה צריכים להשתמש בערכי ניקוד ביטחון כדי להעריך תחזיות ולהחיל ערכי סף מתאימים כדי למטב את אמינות היישומים ולהפחית את הסיכון לתחזיות שעשויות להתבצע על סמך הסתברויות שוליות.
בינה מלאכותית אחראית ואתיקה
חשוב שמהנדסי תוכנה ישקלו את ההשפעה של התוכנה שלהם על המשתמשים, ועל החברה בכלל; לרבות שיקולים אתיים לגבי השימוש בו. כאשר היישום חדור בינה מלאכותית, שיקולים אלה חשובים במיוחד בשל אופי האופן שבו מערכות AI פועלות והחלטות מושכלות; לעתים קרובות מבוסס על מודלים הסתברותיים, אשר בתורם תלויים בנתונים שבהם הם הוכשרו.
האופי דמוי האדם של פתרונות AI הוא יתרון משמעותי בהפיכת יישומים לידידותיים למשתמש, אך הוא גם יכול להוביל משתמשים לתת אמון רב ביכולתה של האפליקציה לקבל החלטות נכונות. הפוטנציאל לפגיעה ביחידים או בקבוצות באמצעות תחזיות שגויות או שימוש לרעה ביכולות AI הוא דאגה מרכזית, ומהנדסי תוכנה הבונים פתרונות התומכים בבינה מלאכותית צריכים ליישם שיקול נאות כדי להפחית סיכונים ולהבטיח הוגנות, אמינות והגנה נאותה מפני נזק או אפליה.
הבנת שיקולים עבור בינה מלאכותית אחראית
היחידה הקודמת הציגה את הצורך בשיקולים לפיתוח אחראי ואתי של תוכנות התומכות בבינה מלאכותית. ביחידה זו, נדון בכמה עקרונות ליבה עבור בינה מלאכותית אחראית שאומצו ב- Microsoft.
הגינות
 מערכות AI צריכות להתייחס לכל האנשים בצורה הוגנת. לדוגמה, נניח שאתה יוצר מודל למידת מכונה כדי לתמוך בבקשה לאישור הלוואה עבור בנק. המודל צריך לחזות אם ההלוואה צריכה להיות מאושרת או לא מבלי לכלול הטיה כלשהי המבוססת על מגדר, מוצא אתני או גורמים אחרים שעלולים לגרום ליתרון או חיסרון לא הוגנים לקבוצות ספציפיות של מועמדים.
מערכות AI צריכות להתייחס לכל האנשים בצורה הוגנת. לדוגמה, נניח שאתה יוצר מודל למידת מכונה כדי לתמוך בבקשה לאישור הלוואה עבור בנק. המודל צריך לחזות אם ההלוואה צריכה להיות מאושרת או לא מבלי לכלול הטיה כלשהי המבוססת על מגדר, מוצא אתני או גורמים אחרים שעלולים לגרום ליתרון או חיסרון לא הוגנים לקבוצות ספציפיות של מועמדים.
הוגנות של מערכות שנלמדו במכונה היא תחום פעיל מאוד במחקר מתמשך, וקיימים פתרונות תוכנה מסוימים להערכה, כימות והפחתה של חוסר הוגנות במודלים שנלמדו במכונה. עם זאת, כלים לבדם אינם מספיקים כדי להבטיח הוגנות. שקול הוגנות מתחילת תהליך פיתוח היישום; סקירה מדוקדקת של נתוני האימון כדי לוודא שהם מייצגים את כל הנושאים שעשויים להיות מושפעים, והערכת ביצועי חיזוי עבור סעיפי משנה של אוכלוסיית המשתמשים שלך לאורך מחזור החיים של הפיתוח.
אמינות ובטיחות
 מערכות AI צריכות לפעול בצורה אמינה ובטוחה. לדוגמה, שקול למערכת תוכנה מבוססת בינה מלאכותית לרכב אוטונומי; או מודל למידת מכונה המאבחן תסמינים של מטופלים וממליץ על מרשמים. חוסר אמינות במערכות מסוג זה עלול לגרום לסיכון משמעותי בחיי אדם.
מערכות AI צריכות לפעול בצורה אמינה ובטוחה. לדוגמה, שקול למערכת תוכנה מבוססת בינה מלאכותית לרכב אוטונומי; או מודל למידת מכונה המאבחן תסמינים של מטופלים וממליץ על מרשמים. חוסר אמינות במערכות מסוג זה עלול לגרום לסיכון משמעותי בחיי אדם.
כמו בכל תוכנה, פיתוח יישומי תוכנה מבוססי בינה מלאכותית חייב להיות נתון לתהליכי בדיקה וניהולי פריסה קפדניים כדי להבטיח שהם יפעלו כצפוי לפני השחרור. בנוסף, מהנדסי תוכנה צריכים לקחת בחשבון את האופי ההסתברותי של מודלים של למידת מכונה , וליישם ערכי סף מתאימים בעת הערכת ציוני ביטחון עבור תחזיות.
פרטיות ואבטחה
 מערכות AI צריכות להיות מאובטחות ואמורות לכבד את הפרטיות. מודלי למידת המכונה שעליהם מבוססות מערכות AI מסתמכים על כמויות גדולות של נתונים, שעשויים להכיל פרטים אישיים שיש לשמור על פרטיותם. גם לאחר שהמודלים מאומנים והמערכת נמצאת בייצור, הם משתמשים בנתונים חדשים כדי לבצע תחזיות או לנקוט פעולה שעשויה להיות כפופה לחששות פרטיות או אבטחה; לכן יש ליישם אמצעי הגנה מתאימים להגנה על נתונים ותוכן של לקוחות.
מערכות AI צריכות להיות מאובטחות ואמורות לכבד את הפרטיות. מודלי למידת המכונה שעליהם מבוססות מערכות AI מסתמכים על כמויות גדולות של נתונים, שעשויים להכיל פרטים אישיים שיש לשמור על פרטיותם. גם לאחר שהמודלים מאומנים והמערכת נמצאת בייצור, הם משתמשים בנתונים חדשים כדי לבצע תחזיות או לנקוט פעולה שעשויה להיות כפופה לחששות פרטיות או אבטחה; לכן יש ליישם אמצעי הגנה מתאימים להגנה על נתונים ותוכן של לקוחות.
הכללה
 מערכות AI צריכות להעצים את כולם ולעורר עניין בקרב אנשים. בינה מלאכותית צריכה להביא תועלת לכל חלקי החברה, ללא קשר ליכולת פיזית, מגדר, נטייה מינית, מוצא אתני או גורמים אחרים.
מערכות AI צריכות להעצים את כולם ולעורר עניין בקרב אנשים. בינה מלאכותית צריכה להביא תועלת לכל חלקי החברה, ללא קשר ליכולת פיזית, מגדר, נטייה מינית, מוצא אתני או גורמים אחרים.
אחת הדרכים למטב את ההכללה היא להבטיח שהעיצוב, הפיתוח והבדיקה של היישום שלך יכללו קלט מקבוצה מגוונת ככל האפשר של אנשים.
שקיפות
 מערכות AI צריכות להיות מובנות. המשתמשים צריכים להיות מודעים לחלוטין למטרת המערכת, כיצד היא פועלת ואילו מגבלות צפויות לה.
מערכות AI צריכות להיות מובנות. המשתמשים צריכים להיות מודעים לחלוטין למטרת המערכת, כיצד היא פועלת ואילו מגבלות צפויות לה.
לדוגמה, כאשר מערכת AI מבוססת על מודל למידת מכונה, עליך בדרך כלל לגרום למשתמשים להיות מודעים לגורמים שעשויים להשפיע על דיוק התחזיות שלה, כגון מספר המקרים המשמשים לאימון המודל, או התכונות הספציפיות שיש להן את ההשפעה הרבה ביותר על התחזיות שלו. עליך גם לשתף מידע על ציון הביטחון עבור תחזיות.
כאשר יישום AI מסתמך על נתונים אישיים, כגון מערכת זיהוי פנים שמצלמת תמונות של אנשים כדי לזהות אותם; עליך להבהיר למשתמש כיצד נעשה שימוש בנתונים שלו ונשמרים, ולמי יש גישה אליהם.
אחריות
 אנשים צריכים להיות אחראים למערכות AI. למרות שנראה כי מערכות AI רבות פועלות באופן אוטונומי, בסופו של דבר זו אחריותם של המפתחים שאימנו ואימתו את המודלים שבהם הם משתמשים, והגדירו את ההיגיון שמבסס החלטות על תחזיות מודלים כדי להבטיח שהמערכת הכוללת עומדת בדרישות האחריות. כדי לסייע בעמידה ביעד זה, מעצבים ומפתחים של פתרון מבוסס בינה מלאכותית צריכים לעבוד במסגרת של עקרונות ממשל וארגון המבטיחים שהפתרון עומד בסטנדרטים אתיים ומשפטיים המוגדרים בבירור.
אנשים צריכים להיות אחראים למערכות AI. למרות שנראה כי מערכות AI רבות פועלות באופן אוטונומי, בסופו של דבר זו אחריותם של המפתחים שאימנו ואימתו את המודלים שבהם הם משתמשים, והגדירו את ההיגיון שמבסס החלטות על תחזיות מודלים כדי להבטיח שהמערכת הכוללת עומדת בדרישות האחריות. כדי לסייע בעמידה ביעד זה, מעצבים ומפתחים של פתרון מבוסס בינה מלאכותית צריכים לעבוד במסגרת של עקרונות ממשל וארגון המבטיחים שהפתרון עומד בסטנדרטים אתיים ומשפטיים המוגדרים בבירור.
הבנה היכולות של למידת מכונה של Azure
הבנת היכולות של למידת מכונה של Azure
Microsoft Azure מספק את שירות למידת המכונה של Azure – פלטפורמה מבוססת ענן להפעלת ניסויים בקנה מידה גדול כדי לאמן מודלים חזויים מנתונים , ולפרסם את המודלים המיומנים כשירותים.
למידת מכונה של Azure מספקת את התכונות והיכולות הבאות:
| תכונה | יכולת |
| למידת מכונה אוטומטית | תכונה זו מאפשרת לאנשים שאינם מומחים ליצור במהירות מודל יעיל של למידת מכונה מנתונים. |
| מעצב למידת מכונה של Azure | ממשק גרפי המאפשר פיתוח ללא קוד של פתרונות למידת מכונה. |
| ניהול נתונים ומחשוב | אחסון נתונים מבוסס ענן ומשאבי מחשוב שמדעני נתונים מקצועיים יכולים להשתמש בהם כדי להריץ קוד ניסוי נתונים בקנה מידה גדול. |
| צינורות Pipeline | מדעני נתונים, מהנדסי תוכנה ומומחי תפעול IT יכולים להגדיר צינורות כדי לתאם משימות הדרכה, פריסה וניהול של מודלים. |
מדעני נתונים יכולים להשתמש ב- Azure Machine Learning לאורך כל מחזור החיים של למידת מכונה כדי:
- לבלוע ולהכין נתונים.
- הפעל ניסויים כדי לחקור נתונים ולאמן מודלים לחיזוי.
- פרוס ונהל מודלים מיומנים כשירותי אינטרנט.
מהנדסי תוכנה עשויים לקיים אינטראקציה עם Azure Machine Learning בדרכים הבאות:
- שימוש בלמידת מכונה אוטומטית או במעצב למידת מכונה של Azure כדי לאמן מודלים של למידת מכונה ולפרוס אותם כשירותי REST שניתן לשלב ביישומים התומכים בבינה מלאכותית.
- שיתוף פעולה עם מדעני נתונים כדי לפרוס מודלים המבוססים על מסגרות נפוצות כגון Scikit-Learn, PyTorch ו- TensorFlow כשירותי אינטרנט, ולצרוך אותם ביישומים.
- שימוש בערכות SDK של למידת מכונה של Azure או בקבצי Script של ממשק שורת פקודה (CLI) כדי לתאם תהליכי DevOps המנהלים ניהול גירסאות, פריסה ובדיקה של מודלים של למידת מכונה כחלק מפתרון כולל לאספקת יישומים.
הבנת היכולות של השירותים הקוגניטיביים של Azure
השירותים הקוגניטיביים של Azure הם שירותים מבוססי ענן המתמצתים את יכולות הבינה המלאכותית. במקום מוצר יחיד, עליך לחשוב על Azure Cognitive Services כקבוצה של שירותים בודדים שבהם תוכל להשתמש כאבני בניין להרכבת יישומים מתוחכמים וחכמים.
שירותים קוגניטיביים מציעים מגוון רחב של יכולות AI מובנות מראש בקטגוריות מרובות, כפי שמוצג בטבלה הבאה.
| שפה | דיבור | חזות | ההחלטה |
| ניתוח טקסט | דיבור לטקסט | ניתוח תמונות | זיהוי אנומליה |
| מענה על שאלות | טקסט לדיבור | ניתוח וידאו | מיתון תוכן |
| הבנת שפה | תרגום דיבור | סיווג תמונות | התאמה אישית של תוכן |
| תרגום | זיהוי רמקולים | זיהוי אובייקטים | |
| ניתוח פנים | |||
| זיהוי תווים אופטי |
שירותי בינה מלאכותית יישומיים
באפשרותך להשתמש בשירותים קוגניטיביים כדי לבנות פתרונות AI משלך, והם גם עומדים בבסיס שירותי הבינה המלאכותית היישומיים של Azure המספקים פתרונות מוכנים לשימוש עבור תרחישי AI נפוצים. שירותי AI יישומיים כוללים:
- Azure Form Recognizer – פתרון זיהוי תווים אופטי (OCR) שיכול לחלץ משמעות סמנטית מטפסים, כגון חשבוניות, קבלות ואחרות.
- Azure Metrics Advisor – שירות המבוסס על השירות הקוגנטיבי של גלאי האנומליה שמפשט את הניטור והתגובה בזמן אמת למדדים קריטיים.
- Azure Video Analyzer for Media – פתרון מקיף למנתחי וידאו המבוסס על השירות הקוגניטיבי Video Indexer.
- Azure Immersive Reader – פתרון קריאה התומך באנשים בכל הגילאים והיכולות.
- Azure Bot Service – שירות ענן לאספקת פתרונות AI לשיחות, או תוכניות Bot.
- חיפוש קוגניטיבי של Azure – פתרון חיפוש בקנה מידה של ענן המשתמש בשירותים קוגניטיביים כדי לחלץ תובנות מנתונים ומסמכים.
הבנת היכולות של שירות הבוטים של Azure
בוטים הם סוכני תוכנה מבוססי בינה מלאכותית שיכולים לעסוק באינטראקציות שיחה. לדוגמה, אתר אינטרנט עשוי לכלול ממשק צ'אט בוט שבו משתמשים יכולים לשלוח שאלות בשפה טבעית ולקבל תגובות לשיחה, או שארגון עשוי להשתמש בבוט כדי לענות לשיחות טלפון נכנסות ולאסוף מידע ראשוני לפני העברת השיחה למפעיל המתאים.
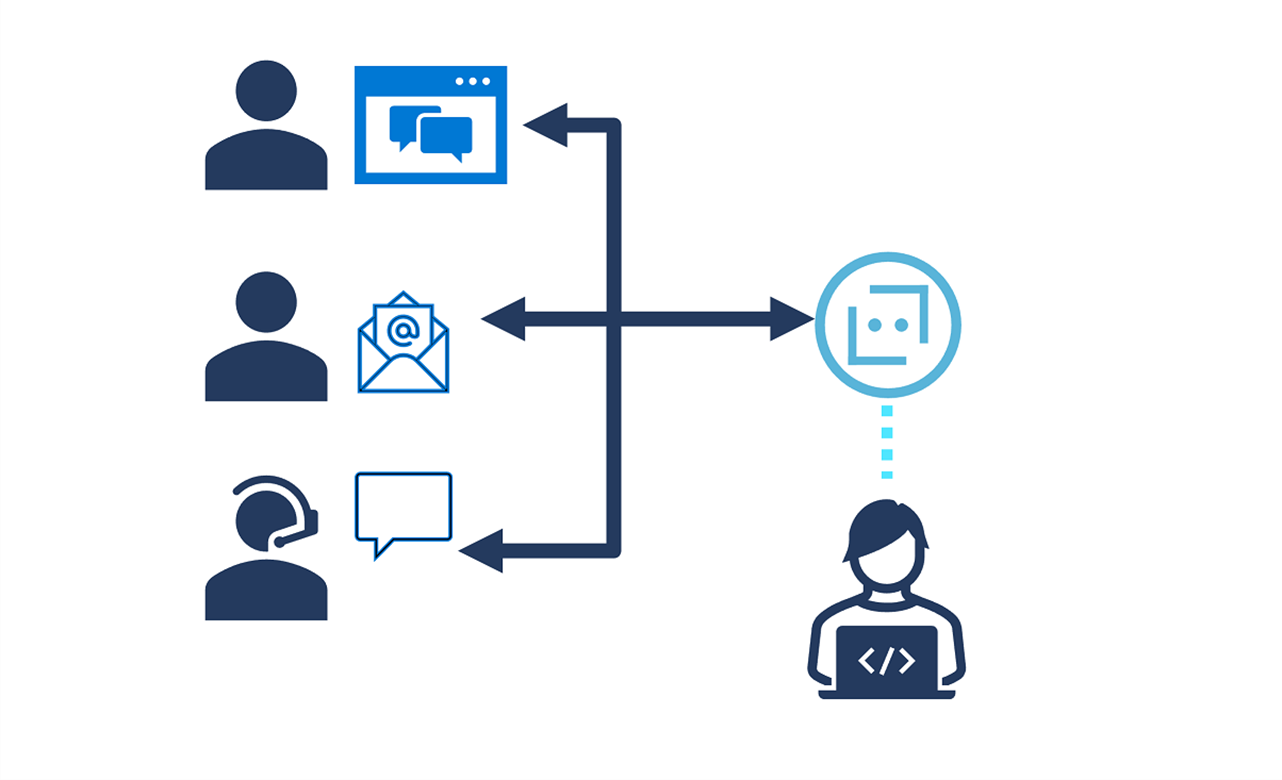
שירות Azure Bot הוא שירות בינה מלאכותית יישומי לפיתוח ואספקה של פתרונות Bot התומכים באינטראקציות שיחה בערוצים מרובים, כגון צ'אט באינטרנט, דואר אלקטרוני, Microsoft Teams ואחרים.
מהנדסי בינה מלאכותית יכולים לפתח בוטים על ידי כתיבת קוד, באמצעות ה – SDK של מסגרת הבוטים. לחלופין, אתה יכול להשתמש ב – Bot Framework Composer כדי לפתח בוטים מורכבים באמצעות ממשק עיצוב חזותי.
הבנת היכולות של החיפוש הקוגניטיבי של Azure
חיפוש מידע הוא דרישה נפוצה ביישומים רבים, החל מאתרי אינטרנט ייעודיים למנועי חיפוש וכלה באפליקציות למכשירים ניידים שיכולות למצוא מידע המתאים להקשר בהתבסס על מיקומך ומה ברצונך להשיג.
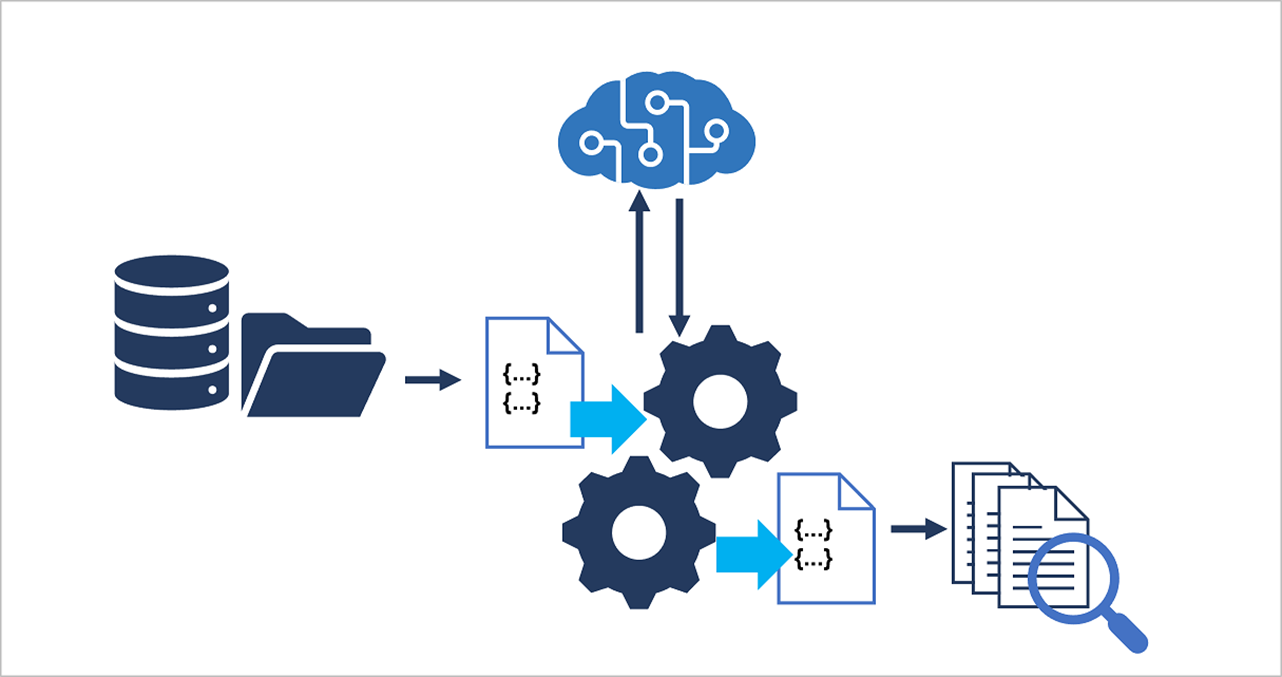
Search הוא שירות בינה מלאכותית יישומי המאפשר לך לקלוט וליצור אינדקס של נתונים ממקורות שונים, ולחפש באינדקס כדי לחפש, לסנן ולמיין מידע שחולץ מנתוני המקור.
בנוסף לאינדקס בסיסי מבוסס טקסט, Azure Cognitive Search מאפשר לך להגדיר צינור (Pipeline) המשתמש במיומנויות AI כדי לשפר את האינדקס עם תובנות הנגזרות מנתוני המקור – לדוגמה, על-ידי שימוש בראייה ממוחשבת וביכולות עיבוד שפה טבעית כדי ליצור תיאורים של תמונות, לחלץ טקסט ממסמכים סרוקים ולקבוע ביטויי מפתח במסמכים גדולים המתמצתים את נקודות המפתח שלהם.
בינה מלאכותית זו מייצרת חוויית חיפוש שימושית יותר, ניתן להתמיד בתובנות שחולצו על-ידי צינור (pipeline) ההעשרה שלך במאגר ידע לצורך ניתוח נוסף או שילוב בצינור נתונים עבור פתרון בינה עסקית.
השירותים הקוגניטיביים של Azure הם שירותים מבוססי ענן המתמצתים את יכולות הבינה המלאכותית. במקום מוצר יחיד, עליך לחשוב על Azure Cognitive Services כקבוצה של שירותים בודדים שבהם תוכל להשתמש כאבני בניין להרכבת יישומים מתוחכמים וחכמים.
שירותים קוגניטיביים כוללים מגוון רחב של שירותי AI בודדים בקטגוריות מרובות, כפי שמוצג בטבלה הבאה.
| שפה | דיבור | חזון | ההחלטה |
| שפה | דיבור | ראייה ממוחשבת | גלאי אנומליה |
| מתרגם | חזון מותאם אישית | מנחה תוכן | |
| פנים | התאמה אישית |
באפשרותך להשתמש בשירותים קוגניטיביים כדי לבנות פתרונות AI משלך, והם גם עומדים בבסיס שירותי הבינה המלאכותית היישומיים של Azure המספקים פתרונות מוכנים לשימוש עבור תרחישי AI נפוצים. שירותי AI יישומיים כוללים:
- Azure Form Recognizer – פתרון זיהוי תווים אופטי (OCR) שיכול לחלץ משמעות סמנטית מטפסים, כגון חשבוניות, קבלות ואחרות.
- Azure Metrics Advisor – שירות המבוסס על השירות הקוגנטיבי של גלאי האנומליה שמפשט את הניטור והתגובה בזמן אמת למדדים קריטיים.
- Azure Video Analyzer for Media – פתרון מקיף למנתחי וידאו המבוסס על השירות הקוגניטיבי Video Indexer.
- Azure Immersive Reader – פתרון קריאה התומך באנשים בכל הגילאים והיכולות.
- Azure Bot Service – שירות ענן לאספקת פתרונות AI לשיחות, או תוכניות Bot.
- חיפוש קוגניטיבי של Azure – פתרון חיפוש בקנה מידה של ענן המשתמש בשירותים קוגניטיביים כדי לחלץ תובנות מנתונים ומסמכים.
בעוד שהפרטים של כל שירות קוגניטיבי יכולים להשתנות, הגישה להקצאתם ולצריכתם היא בדרך כלל זהה.
הקצאת משאב שירותים קוגניטיביים
השירותים הקוגניטיביים של Azure כוללים מגוון רחב של יכולות AI שבהן תוכל להשתמש ביישומים שלך. כדי להשתמש בכל אחד מהשירותים הקוגניטיביים, עליך ליצור משאבים מתאימים במנוי Azure כדי להגדיר נקודת קצה שבה ניתן לצרוך את השירות, לספק מפתחות גישה לגישה מאומתת ולנהל את החיוב עבור השימוש של היישום שלך בשירות.
אפשרויות עבור משאבי Azure
עבור רבים מהשירותים הקוגניטיביים הזמינים, באפשרותך לבחור בין אפשרויות ההקצאה הבאות:
משאב מרובה שירותים
באפשרותך להקצות משאב שירותים קוגנטיביים התומך במספר שירותים קוגניטיביים שונים. לדוגמה, באפשרותך ליצור משאב יחיד המאפשר לך להשתמש בשפה, בראייה ממוחשבת, בדיבור ובשירותים אחרים.
גישה זו מאפשרת לך לנהל קבוצה אחת של אישורי גישה כדי לצרוך שירותים מרובים בנקודת קצה אחת, ועם נקודת חיוב אחת עבור השימוש בכל השירותים.
משאב בשירות יחיד
ניתן להקצות כל שירות קוגניטיבי בנפרד, לדוגמה על-ידי יצירת משאבי שפה וראייה ממוחשבת נפרדים במנוי Azure שלך.
גישה זו מאפשרת לך להשתמש בנקודות קצה נפרדות עבור כל שירות (לדוגמה, להקצות אותן באזורים גיאוגרפיים שונים) ולנהל אישורי גישה עבור כל שירות בנפרד. הוא גם מאפשר לך לנהל את החיוב בנפרד עבור כל שירות.
משאבים של שירות יחיד מציעים בדרך כלל שכבה חינמית (עם הגבלות שימוש), מה שהופך אותם לבחירה טובה לנסות שירות לפני השימוש בו ביישום ייצור.
משאבי הדרכה וחיזוי
בעוד שניתן להשתמש ברוב השירותים הקוגניטיביים באמצעות משאב Azure יחיד, חלקם מציעים (או דורשים) משאבים נפרדים לאימון וחיזוי מודלים. הדבר מאפשר לך לנהל חיוב עבור אימון מודלים מותאמים אישית בנפרד מצריכת המודל לפי יישומים, וברוב המקרים מאפשר לך להשתמש במשאב ייעודי ספציפי לשירות כדי לאמן מודל, אך במשאב כללי של Cognitive Services כדי להפוך את המודל לזמין ליישומים לצורך הסקה.
זיהוי נקודות קצה ומפתחות
כאשר אתה מקצה משאב שירות קוגנטיבי במנוי Azure שלך, אתה מגדיר נקודת קצה שדרכה יישום יכול לצרוך את השירות.
כדי לצרוך את השירות דרך נקודת הקצה, יישומים דורשים את המידע הבא:
- נקודת הקצה URI. זוהי כתובת ה- HTTP שבה ניתן לגשת לממשק REST עבור השירות. רוב ערכות פיתוח התוכנה (SDK) של השירותים הקוגניטיביים משתמשות ב- URI של נקודת הקצה כדי ליזום חיבור לנקודת הקצה.
- מפתח מנוי. הגישה לנקודת הקצה מוגבלת בהתבסס על מפתח מנוי. יישומי לקוח חייבים לספק מפתח חוקי כדי לצרוך את השירות. כאשר אתה מספק משאב שירותים קוגניטיביים, נוצרים שני מפתחות – יישומים יכולים להשתמש בכל אחד מהמפתחות. באפשרותך גם ליצור מחדש את המפתחות כנדרש כדי לשלוט בגישה למשאב שלך.
- מיקום המשאב. בעת הקצאת משאב ב- Azure, אתה בדרך כלל מקצה אותו למיקום, הקובע את מרכז הנתונים של Azure שבו מוגדר המשאב. בעוד שרוב ערכות ה- SDK משתמשות ב- URI של נקודת הקצה כדי להתחבר לשירות, חלקן דורשות את המיקום.
שימוש ב- REST API
שירותים קוגניטיביים מספקים ממשקי תיכנות יישומים (API) של REST שיישומי לקוח יכולים להשתמש בהם כדי לצרוך שירותים. ברוב המקרים, ניתן לקרוא לפונקציות שירות על-ידי שליחת נתונים בתבנית JSON על פני בקשת HTTP, שעשויה להיות בקשת POST, PUT או GET בהתאם לפונקציה הספציפית הנקראת. תוצאות הפונקציה מוחזרות ללקוח כתגובת HTTP, לעתים קרובות עם תוכן JSON העוטף את נתוני הפלט מהפונקציה.
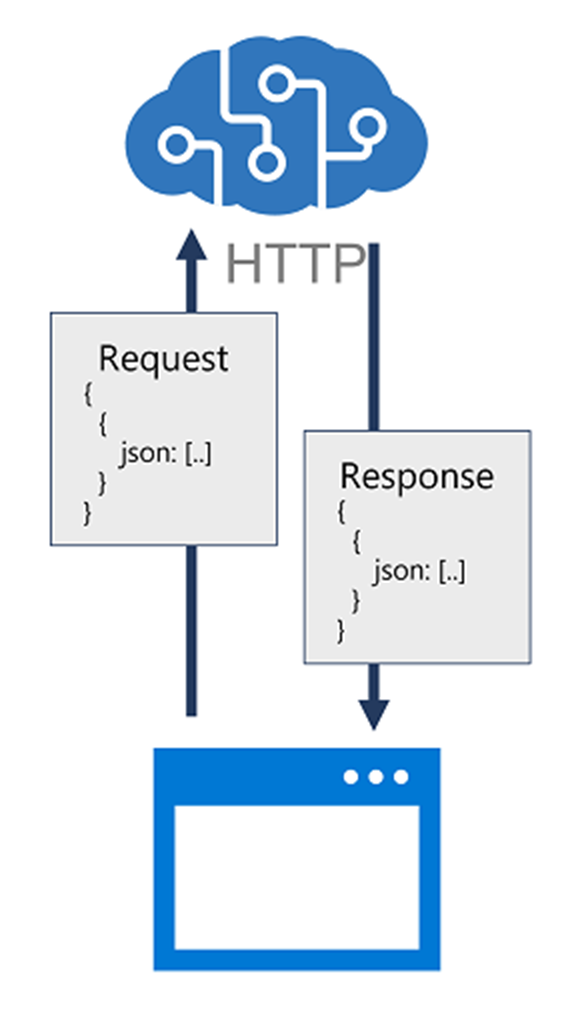
השימוש בממשקי REST עם נקודת קצה של HTTP פירושו שכל שפת תכנות או כלי המסוגלים להגיש ולקבל JSON over HTTP יכולים לשמש לצריכת שירותים קוגניטיביים. באפשרותך להשתמש בשפות תכנות נפוצות כגון Microsoft C# , Python ו- JavaScript; כמו גם כלי עזר כגון Postman ו cURL, אשר יכול להיות שימושי לבדיקה.
שימוש ב-SDK
באפשרותך לפתח יישום המשתמש בשירותים קוגניטיביים באמצעות ממשקי REST, אך קל יותר לבנות פתרונות מורכבים יותר באמצעות ספריות מקוריות עבור שפת התכנות שבה אתה מפתח את היישום.
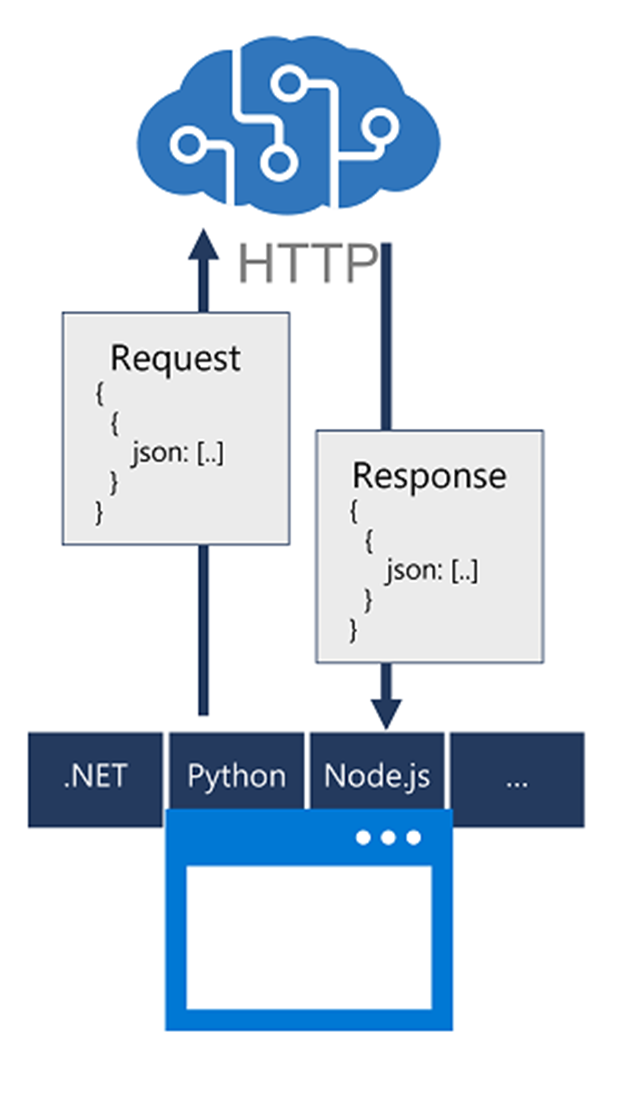
ערכות פיתוח תוכנה (SDK) עבור שפות תכנות נפוצות מופשטות ממשקי REST עבור רוב השירותים הקוגניטיביים. זמינות SDK משתנה בהתאם לשירותים קוגניטיביים בודדים, אך עבור רוב השירותים יש SDK עבור שפות כגון:
- מיקרוסופט C# (.NET Core)
- Phyton
- JavaScript (node.js)
- JAVA
כל SDK כולל חבילות שבאפשרותך להתקין כדי להשתמש בספריות ספציפיות לשירות בקוד שלך, ותיעוד מקוון שיסייע לך לקבוע את הכיתות, השיטות והפרמטרים המתאימים המשמשים לעבודה עם השירות.
שירותי השפה בבינה מלאכותית
מדי יום, העולם מייצר כמות עצומה של נתונים; חלק גדול ממנו מבוסס טקסט בצורה של הודעות דוא"ל, פוסטים במדיה החברתית, ביקורות מקוונות, מסמכים עסקיים ועוד. טכניקות בינה מלאכותית המיישמות מודלים סטטיסטיים וסמנטיים מאפשרות לך ליצור יישומים המחלצים משמעות ותובנות מנתונים מבוססי טקסט אלה.
השפה Azure Cognitive Service מספק API עבור טכניקות ניתוח טקסט נפוצות שבאפשרותך לשלב בקלות בקוד היישום שלך.
במודול זה, תלמד כיצד להשתמש בשירות השפה כדי:
- זיהוי שפה
- חילוץ ביטויי מפתח
- ניתוח סנטימנט
- חילוץ ישויות
- חילוץ ישויות מקושרות
הקצאת משאב שפה
שירות השפה נועד לסייע לך לחלץ מידע מטקסט. הוא מספק פונקציונליות שבה באפשרותך להשתמש עבור:
- זיהוי שפה – קביעת השפה שבה נכתב הטקסט.
- חילוץ ביטויי מפתח – זיהוי מילים וביטויים חשובים בטקסט המציינים את הנקודות העיקריות.
- ניתוח סנטימנט – כימות עד כמה הטקסט חיובי או שלילי.
- זיהוי ישויות בעלות שם – זיהוי הפניות לישויות, כולל אנשים, מיקומים, תקופות זמן, ארגונים ועוד.
- קישור ישויות – זיהוי ישויות ספציפיות על ידי מתן קישורי הפניה לערכים בוויקיפדיה.
משאבי Azure לניתוח טקסט
כדי להשתמש בשירות השפה לניתוח טקסט, עליך להקצות עבורו משאב במנוי Azure שלך. באפשרותך להקצות משאב שפה בשירות יחיד , או להשתמש במשאב שירותים קוגניטיביים מרובה שירותים .
לאחר שהקצית משאב מתאים במנוי Azure שלך, באפשרותך להשתמש בנקודת הקצה שלו ובאחד ממפתחות המנוי שלו כדי להתקשר לממשקי ה- API של השפה מהקוד שלך. באפשרותך להתקשר לממשקי ה- API של השפה על-ידי שליחת בקשות בתבנית JSON לממשק REST, או על-ידי שימוש בכל אחד מערכות ה- SDK הספציפיות לשפת התיכנות הזמינות.
זיהוי שפה
ה- API של זיהוי השפה מעריך קלט טקסט, ועבור כל מסמך שנשלח, מחזיר מזהי שפה עם ניקוד המציין את עוצמת הניתוח. שירות השפה מזהה עד 120 שפות.
יכולת זו שימושית עבור מאגרי תוכן האוספים טקסט שרירותי, כאשר השפה אינה ידועה. תרחיש אחר יכול לכלול בוט צ'אט. אם משתמש מתחיל הפעלה עם בוט הצ'אט, ניתן להשתמש בזיהוי שפה כדי לקבוע באיזו שפה הוא משתמש ולאפשר לך להגדיר את תגובות הבוט שלך בשפה המתאימה.
באפשרותך לנתח את התוצאות של ניתוח זה כדי לקבוע באיזו שפה נעשה שימוש במסמך הקלט. התגובה גם מחזירה ניקוד, המשקף את הביטחון של המודל (ערך בין 0 ל-1).
זיהוי שפה יכול לעבוד עם מסמכים או ביטויים בודדים. חשוב לציין שגודל המסמך חייב להיות מתחת ל-5,120 תווים. מגבלת הגודל היא לכל מסמך וכל אוסף מוגבל ל- 1,000 פריטים (מזהים). דוגמה של מטען JSON מעוצב כראוי שאתה עשוי לשלוח לשירות בגוף הבקשה מוצגת כאן, כולל אוסף של מסמכים, שכל אחד מהם מכיל מזהה ייחודי והטקסט שיש לנתח. לחלופין, באפשרותך לספק מדינהHint כדי לשפר את ביצועי החיזוי.
JSON
{
"Documents": [
{
"countryHint": "USA",
"ID": "1",
"Text": "Hello world"
},
{
"ID": "2",
"Text": "Hello everyone"
}
]
}
השירות יחזיר תגובת JSON המכילה תוצאה עבור כל מסמך בגוף הבקשה, כולל השפה החזויה וערך המציין את רמת הביטחון של החיזוי. רמת הביטחון היא ערך הנע בין 0 ל-1 כאשר ערכים קרובים יותר ל-1 הם רמת ביטחון גבוהה יותר. הנה דוגמה לתגובת JSON סטנדרטית שממפה לבקשה הנ"ל JSON.
JSON
{
"Documents": [
{
"ID": "1",
"detectedLanguage": {
"Name": "English",
"iso6391Name": "en",
"Self-confidence": 1
},
"Warnings": []
},
{
"ID": "2",
"detectedLanguage": {
"Name": "French",
"iso6391Name": "fr",
"Self-confidence": 1
},
"Warnings": []
}
],
"Errors": [],
"modelVersion": "2020-04-01"
}
במדגם שלנו, כל השפות מראות ביטחון של 1, בעיקר משום שהטקסט פשוט יחסית וקל לזהות את השפה.
אם תעביר מסמך הכולל תוכן רב-לשוני, השירות יפעל באופן שונה במקצת. תוכן בשפות מעורבות באותו מסמך מחזיר את השפה עם הייצוג הגדול ביותר בתוכן, אך עם דירוג חיובי נמוך יותר, המשקף את העוצמה השולית של הערכה זו. בדוגמה הבאה, הקלט הוא שילוב של אנגלית, ספרדית וצרפתית. המנתח משתמש בניתוח סטטיסטי של הטקסט כדי לקבוע את השפה השלטת .
JSON
{
"Documents": [
{
"ID": "1",
"Text": "Hello, I want to take a class at your university. Do you offer Spanish lessons? It's my first language and easiest to write. Que diriez-vous des cours en français?"
}
]
}
הדוגמה הבאה מציגה תגובה עבור דוגמה מרובת שפות זו.
JSON
{
"Documents": [
{
"ID": "1",
"Recognized languages": [
{
"Name": "Spanish",
"iso6391Name": "It",
"Score": 0.9375
}
]
}
],
"Errors": []
}
התנאי האחרון שיש לקחת בחשבון הוא כאשר קיימת עמימות לגבי תוכן השפה. התרחיש עשוי להתרחש אם תשלח תוכן טקסטואלי שהמנתח אינו יכול לנתח, לדוגמה עקב בעיות בקידוד תווים בעת המרת הטקסט למשתנה מחרוזת. כתוצאה מכך, התגובה עבור שם השפה וקוד ISO תציין (לא ידוע) וערך הניקוד יוחזר כ- NaN, או Not a Number. הדוגמה הבאה מראה כיצד תיראה התגובה.
JSON
{
"ID": "5",
"Recognized languages": [
{
"Name": "(Unknown)",
"iso6391Name": "(Unknown)",
"Score"": """NaN"
}
]
חילוץ ביטויי מפתח
חילוץ ביטויי מפתח הוא התהליך של הערכת הטקסט של מסמך, או מסמכים, ולאחר מכן זיהוי הנקודות העיקריות סביב ההקשר של המסמכים.
חילוץ ביטויי מפתח פועל בצורה הטובה ביותר עבור מסמכים גדולים יותר (הגודל המרבי שניתן לנתח הוא 5,120 תווים).
כמו בזיהוי שפה, ממשק REST מאפשר לך לשלוח מסמך אחד או יותר לניתוח.
JSON
{
"Documents": [
{
"ID": "1",
"שפה": "in",
"Text": "You must have the change you want
to see in the world."
},
{
"ID": "2",
"שפה": "in",
"Text": "A journey of a thousand miles
Starts with one step."
}
]
}
התגובה מכילה רשימה של ביטויי מפתח שזוהו בכל מסמך.
Jason
{
"Documents": [
{
"ID": "1",
"Key phrases": [
"Change",
"World"
],
"Warnings": []
},
{
"ID": "2",
"Key phrases": [
"Miles",
"One step,"
"Journey"
],
"Warnings": []
}
],
"Errors": [],
"modelVersion": "2020-04-01"
}
ניתוח סנטימנט
ניתוח סנטימנט משמש כדי להעריך עד כמה מסמך טקסט הוא חיובי או שלילי, אשר יכול להיות שימושי בעומסי עבודה שונים, כגון:
- הערכת סרט, ספר או מוצר על ידי כימות סנטימנט על סמך ביקורות.
- מתן עדיפות לתגובות שירות לקוחות להתכתבויות המתקבלות באמצעות הודעות דוא"ל או מדיה חברתית.
בעת שימוש בשירות השפה להערכת סנטימנט, התגובה כוללת סנטימנט מסמך כולל וסנטימנט משפט בודד עבור כל מסמך שנשלח לשירות.
לדוגמה, באפשרותך לשלוח מסמך יחיד לניתוח סנטימנט כך:
Jason
{
"Documents": [
{
"שפה": "in",
"ID": "1",
"Text": "Smile! Life is good!"
}
]
}
The response from the service may look like this:
Jason
{
"Documents": [
{
"ID": "1",
"Sentiment": "Positive",
"Self-confidence": {
"Positive": 0.99,
"Neutral": 0.01,
"Negative": 0.00
},
"Sentences": [
{
"Text": "Smile!",
"Sentiment": "Positive",
"Self-confidence": {
"Positive": 0.97,
"Neutral": 0.02,
"Negative": 0.01
},
"Offset": 0,
"Length": 6
},
{
"Text": "Life is good!",
"Sentiment": "Positive",
"Self-confidence": {
"Positive": 0.98,
"Neutral": 0.02,
"Negative": 0.00
},
"Offset": 7,
"Length": 13
}
],
"Warnings": []
}
],
"Errors": [],
"modelVersion": "2020-04-01"
}
סנטימנט משפטים מבוסס על ציוני ביטחון עבור ערכי סיווג חיוביים, שליליים וניטרליים בין 0 ל-1.
הסנטימנט הכללי של המסמך מבוסס על משפטים:
- אם כל המשפטים הם ניטרליים, הסנטימנט הכללי הוא נייטרלי.
- אם סיווגי משפטים כוללים רק חיובי וניטרלי, הסנטימנט הכללי הוא חיובי.
- אם סיווגי המשפטים כוללים רק שלילי וניטרלי, הסנטימנט הכללי הוא שלילי.
- אם סיווגי המשפטים כוללים חיוביים ושליליים, הסנטימנט הכללי מעורבב.
חילוץ ישויות
זיהוי ישות בשם מזהה ישויות המוזכרות בטקסט. ישויות מקובצות לקטגוריות ולקטגוריות משנה, לדוגמה:
- אדם
- מקום
- תאריך שעה
- ארגון
- כתובת
- דואר אלקטרוני
- כתובת URL
קלט עבור זיהוי ישות דומה לקלט עבור פונקציות API אחרות של שפה:
Jason
{
"Documents": [
{
"Language": "in",
"ID": "1",
"Text": "Joe went to London on Saturday"
}
]
}
התשובה כוללת רשימה של ישויות המסווגות לקטגוריות הנמצאות בכל מסמך:
Jason
{
"Documents":[
{
"ID":"1",
"Entities":[
{
"Text":"Joe",
"Category":"Person",
"Offset":0,
"Length":3,
"SecurityScore":0.62
},
{
"Text":"London",
"Category":"Location",
"Subcategory":"GPE",
"Offset":12,
"Length":6,
"SecurityScore":0.88
},
{
"Text":"Shabbat",
"Category":"DateTime",
"Subcategory":"Date",
"Offset":22,
"Length":8,
"SecurityScore":0.8
}
],
"Warnings":[]
}
],
"Errors":[],
"modelVersion":"2021-01-15"
}
חילוץ ישויות מקושרות
במקרים מסוימים, אותו שם עשוי לחול על יותר מישות אחת. לדוגמה, האם מופע של המילה "נוגה" מתייחס לכוכב הלכת או לאלה היוונית?
ניתן להשתמש בקישור ישויות כדי לנטרל ישויות בעלות אותו שם על-ידי הפניה למאמר במאגר ידע. ויקיפדיה מספקת את בסיס הידע עבור שירות ניתוח טקסט. קישורים ספציפיים למאמרים נקבעים על סמך הקשר הישות בתוך הטקסט.
לדוגמה, "ראיתי את ונוס זורחת בשמיים" קשורה לקישור https://en.wikipedia.org/wiki/Venus; ואילו "ונוס, אלת היופי" קשורה ל https://en.wikipedia.org/wiki/Venus_(מיתולוגיה).
כמו בכל פונקציות שירות השפה, באפשרותך לשלוח מסמך אחד או יותר לניתוח:
Jason
{
"Documents": [
{
"שפה": "in",
"ID": "1",
"Text": "I saw Venus shining in the sky"
}
]
}
התגובה כוללת את הישויות המזוהות בטקסט יחד עם קישורים למאמרים משויכים:
Jason
{
"Documents":
[
{
"ID":"1",
"Entities":[
{
"Name":"Venus",
"Adjustments":[
{
"Text":"Venus",
"Offset":6,
"Length":5,
"SecurityScore":0.01
}
],
"שפה":"in",
"id":"נוגה",
"url":"https://en.wikipedia.org/wiki/Venus",
"Data source":"Wikipedia"
}
],
"Warnings":[]
}
],
"Errors":[],
"modelVersion":"2020-02-01"
}
תרגום טקסט באמצעות שירות 'מתרגם' בבינה מלאכותית
ישנן שפות נפוצות רבות ברחבי העולם, והיכולת להחליף מידע בין דוברי שפות שונות היא לעתים קרובות דרישה קריטית לפתרונות גלובליים.
השירות הקוגניטיבי של Azure המתרגם מספק API לתרגום טקסט בין 90 שפות נתמכות.
- הקצאת משאב מתרגם
- הבנת זיהוי שפה, תרגום ותעתיק
- ציון אפשרויות תרגום
- הגדרת תרגומים מותאמים אישית
הקצאת משאב מתרגם
שירות ' מתרגם' מספק API רב-לשוני לתרגום טקסט שניתן להשתמש בו עבור:
- זיהוי שפה
- תרגום אחד לרבים
- תעתיק סקריפט (המרת טקסט מהסקריפט המקורי שלו לסקריפט חלופי).

משאבים עבור מתרגם של Azure
כדי להשתמש בשירות 'מתרגם', עליך להקצות עבורו משאב במנוי Azure שלך. באפשרותך להקצות משאב מתרגם בשירות יחיד , או להשתמש ב- API של ניתוח טקסט במשאב שירותים קוגניטיביים מרובה שירותים .
לאחר שהקצית משאב מתאים במנוי Azure שלך, באפשרותך להשתמש במיקום שבו פרסת את המשאב ובאחד ממפתחות המנוי שלו כדי להתקשר לממשקי ה- API של המתרגם מהקוד שלך. באפשרותך להתקשר לממשקי ה- API של המתרגם על-ידי שליחת בקשות בתבנית JSON לממשק REST, או על-ידי שימוש בכל אחד מערכות ה- SDK הספציפיות לשפת התכנות הזמינות.
הבנת זיהוי שפה, תרגום ותעתיק
יכולות של שירות 'מתרגם '.
זיהוי שפה
באפשרותך להשתמש בפונקציה detect REST כדי לזהות את השפה שבה נכתב טקסט.
לדוגמה, באפשרותך לשלוח את הבקשה הבאה.
Jason
{ Text :’Hello’}
התגובה לבקשה זו נראית כך, ומציינת שהטקסט כתוב ביפנית:
Jason
[ { “isTranslationSupported”: That’s right, “isTransliterationSupported”: That’s right,“Language”:”And”, “Score”: 1.0 }]
תרגום
כדי לתרגם טקסט משפה אחת לאחרת, השתמש בפונקציית התרגום; ציון פרמטר יחיד מתוך כדי לציין את שפת המקור, ופרמטר אחד או יותר כדי לציין את השפות שאליהן ברצונך לתרגם את הטקסט.
לדוגמה, באפשרותך לשלוח את אותו JSON שבו השתמשנו בעבר כדי לזהות את השפה, תוך ציון פרמטר מ- של ja (יפנית) ושניים לפרמטרים עם הערכים en (אנגלית) ו- fr (צרפתית). פעולה זו תניב את התוצאה הבאה:
Jason
[ {“Translations”: [{“text”: “Hello”, “to”: “en”}, {“טקסט”: “Bonjour”, “to”: “fr”} ] }]
תעתיק
הטקסט היפני שלנו נכתב באמצעות סקריפט היראגאנה, כך שבמקום לתרגם אותו לשפה אחרת, ייתכן שתרצה לתמלל אותו לסקריפט אחר – למשל כדי לעבד את הטקסט בכתב לטיני (כפי שמשמש טקסט בשפה האנגלית).
כדי להשיג זאת, אנו יכולים לשלוח את הטקסט היפני לפונקציית התעתיק עם פרמטר fromScript של Jpan ופרמטר toScript של Latin כדי לקבל את התוצאה הבאה:
Jason
[ {"תסריט": "Latn","טקסט": "Kon'nichiwa" }]
ציון אפשרויות תרגום
פונקציית התרגום תומכת בפרמטרים רבים המשפיעים על הפלט.
יישור מילים
באנגלית כתובה (תוך שימוש בכתב לטיני), רווחים משמשים להפרדת מילים. עם זאת, בכמה שפות אחרות (וליתר דיוק, סקריפטים) זה לא תמיד המקרה.
לדוגמה, תרגום "שירותים קוגניטיביים" מ- en (אנגלית) ל– zh (סינית פשוטה) מייצר את התוצאה "认知服务", וקשה להבין את הקשר בין הדמויות בטקסט המקור לבין התווים המתאימים בתרגום. כדי לפתור בעיה זו, באפשרותך לציין את הפרמטר include Alignment עם ערך של true כדי להפיק את התוצאה הבאה:
Jason
[ {"Translations": [{"טקסט": "שירותים קוגניטיביים", "אל": "zh-Hans","alignment": {"proj": "0:8-0:1 10:17-2:3"} } ] }]
תוצאות אלה אומרות לנו שתווים 0 עד 8 במקור מתאימים לתווים 0 עד 1 בתרגום , ואילו תווים 10 עד 17 במקור תואמים לתווים 2 עד 3 בתרגום.
אורך המשפט
לפעמים כדאי לדעת את אורך התרגום, לדוגמה כדי לקבוע כיצד להציג אותו בצורה הטובה ביותר בממשק משתמש. באפשרותך לקבל מידע זה על-ידי הגדרת הפרמטר include Sentence Length ל– true.
לדוגמה, ציון פרמטר זה בעת תרגום הטקסט באנגלית (en) "Hello world!" לצרפתית (fr) מפיק את התוצאות הבאות:
Jason
[ {"Translations": [{"Text":"Hello everyone!" ,"To":"fr","sentLen":{"srcSentLen":[12], "transSentLen":[20]} } ] }]
סינון ניבולי פה
לעתים טקסט מכיל ניבולי פה, שייתכן שתרצה לטשטש או להשמיט לחלוטין בתרגום. באפשרותך לטפל בניבולי פה על-ידי ציון הפרמטר provenity Action , שיכול לכלול אחד מהערכים הבאים:
- NoAction: ניבולי פה מתורגמים יחד עם שאר הטקסט.
- נמחק: ניבולי פה מושמטים בתרגום.
- מסומן: ניבולי פה מסומנים באמצעות הטכניקה המצוינת בפרמטר pronavityMarker (אם סופק). ערך ברירת המחדל עבור פרמטר זה הוא כוכבית, המחליפה תווים בניבולי פה ב- "*". כחלופה, ניתן לציין ערך גסות של Tag, הגורם להכללת גסויות בתגי XML.
לדוגמה, תרגום הטקסט באנגלית (en) "JSON הוא נהדר!" (כאשר המילה החסומה היא ניבולי פה) לצרפתית (fr) עם ניבולי פהפעולה של מסומן וניבולי פהMarker של כוכבית מפיקה את התוצאה הבאה:
Jason
[ {"Translations": [{"text": "JSON est *** génial!" ,"To":"fr"} ] }]
הגדרת תרגומים מותאמים אישית
בעוד שמודל התרגום המוגדר כברירת מחדל המשמש את שירות המתרגם יעיל עבור תרגום כללי, ייתכן שיהיה עליך לפתח פתרון תרגום עבור עסקים או תעשיות שבהם יש אוצר מילים ספציפי של מונחים הדורשים תרגום מותאם אישית.
כדי לפתור בעיה זו, באפשרותך ליצור מודל מותאם אישית הממפה קבוצות משלך של מונחי מקור ויעד לתרגום. כדי ליצור מודל מותאם אישית, השתמש בפורטל מתרגם מותאם אישית כדי:
- יצירת סביבת עבודה המקושרת למשאב 'מתרגם'
- יצירת פרוייקט
- העלאת קבצי נתוני אימון
- לאמן מודל
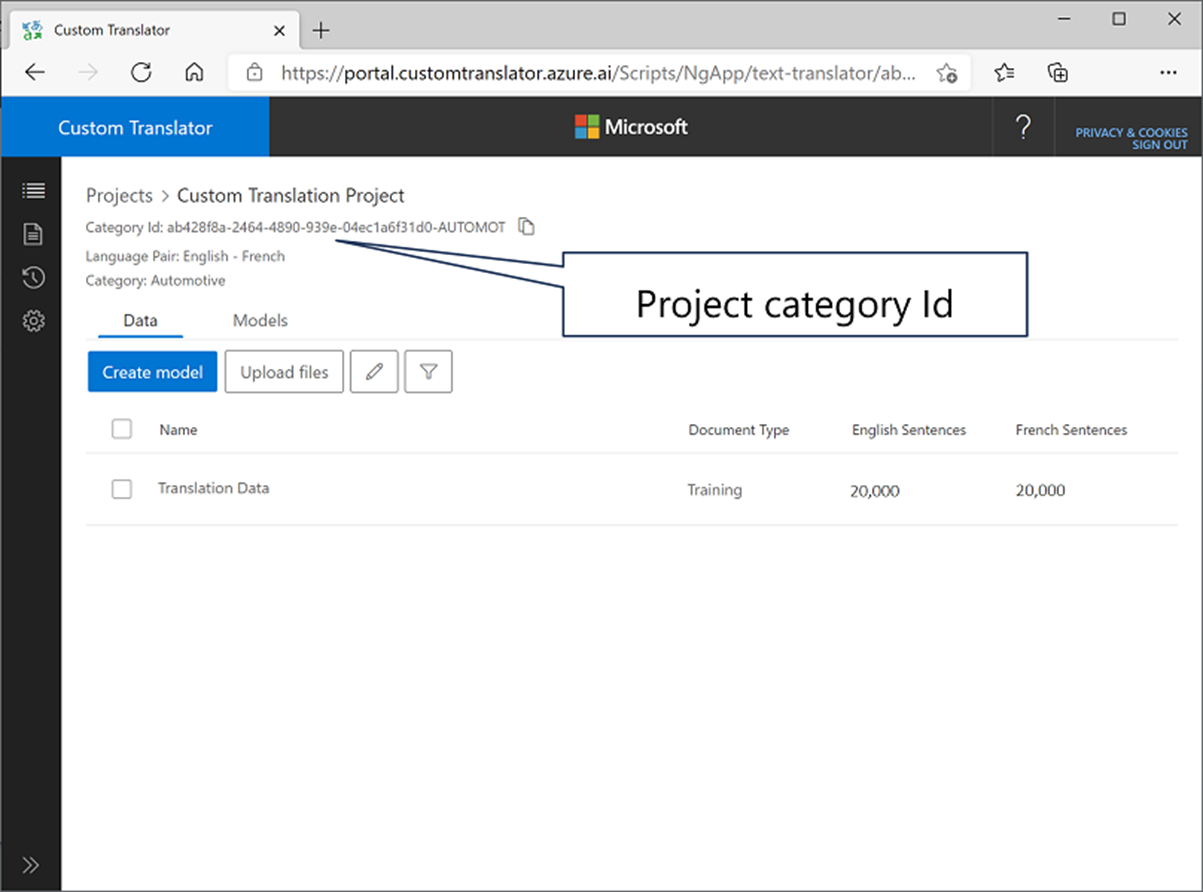
למודל המותאם אישית שלך מוקצה מזהה קטגוריה ייחודי, שאותו באפשרותך לציין בקריאות תרגום למשאב המתרגם שלך באמצעות פרמטר הקטגוריה, מה שגורם לתרגום להתבצע על-ידי המודל המותאם אישית שלך במקום על-ידי מודל ברירת המחדל.
יצירת אפליקציות המותאמות לשימוש בדיבור בבינה מלאכותית
שירות הדיבור מספק ממשקי API שבהם באפשרותך להשתמש כדי לבנות יישומים התומכים בדיבור.
באופן ספציפי, שירות הדיבור תומך ב:
- דיבור לטקסט: API המאפשר זיהוי דיבור שבו היישום שלך יכול לקבל קלט מדובר.
- טקסט לדיבור: API המאפשר סינתזת דיבור שבה היישום שלך יכול לספק פלט מדובר.
- תרגום דיבור: API שבו באפשרותך להשתמש כדי לתרגם קלט מדובר לשפות מרובות.
- זיהוי רמקולים: API המאפשר ליישום שלך לזהות רמקולים בודדים על סמך קולם.
- זיהוי כוונות: API המשתלב עם שירות הבנת השפה כדי לקבוע את המשמעות הסמנטית של קלט מדובר.
מודול זה מתמקד בזיהוי דיבור ובסינתזת דיבור, שהן יכולות הליבה של כל יישום התומך בדיבור.
מטרות הלמידה
- הקצאת משאב Azure עבור שירות הדיבור
- שימוש ב- API של דיבור לטקסט כדי ליישם זיהוי דיבור
- השתמש ב- API של טקסט לדיבור כדי ליישם סינתזת דיבור
- קביעת תצורה של פורמט שמע וקולות
- שימוש בשפת סימון של סינתזת דיבור (SSML)
היחידות במודול כוללות מידע מושגי חשוב על שירות הדיבור וכיצד להשתמש ב- API שלו באמצעות אחת מערכות פיתוח התוכנה (SDK) הנתמכות, ולאחר מכן תוכל לנסות את שירות הדיבור בעצמך בתרגיל מעשי. כדי להשלים את התרגיל המעשי, תזדקק למנוי של Microsoft Azure. אם עדיין אין לך תוכנית כזו, תוכל להירשם לגירסת ניסיון ללא תשלום ב-https://azure.com/free.
הקצאת משאב Azure לדיבור
לפני שתוכל להשתמש בשירות הדיבור, עליך ליצור משאב דיבור במנוי Azure שלך. באפשרותך להשתמש במשאב דיבור ייעודי או במשאב שירותים קוגניטיביים מרובה שירותים .
לאחר יצירת משאב Azure, תזדקק למידע הבא כדי להשתמש בו מיישום לקוח באמצעות אחת מערכות ה- SDK הנתמכות:
- המיקום שבו המשאב נפרס (לדוגמה, eastus)
- אחד המפתחות שהוקצו למשאב שלך.
באפשרותך להציג ערכים אלה בדף מפתחות ונקודות קצה עבור המשאב שלך בפורטל Azure.
שימוש ב- API של דיבור לטקסט
שירות הדיבור תומך בזיהוי דיבור באמצעות שני ממשקי API של REST:
- ה- API של דיבור לטקסט , שהוא הדרך העיקרית לביצוע זיהוי דיבור.
- ה-API של שמע קצר דיבור לטקסט , הממוטב לזרמים קצרים של שמע (עד 60 שניות).
באפשרותך להשתמש בכל אחד מה- API לזיהוי דיבור אינטראקטיבי, בהתאם לאורך הצפוי של הקלט המדובר. ניתן גם להשתמש ב – API של דיבור לטקסט לתמלול אצווה, תוך תמלול קבצי שמע מרובים לטקסט כפעולת אצווה.
באפשרותך לקבל מידע נוסף על ממשקי ה- API של REST בתיעוד ממשקי ה- API של REST של דיבור לטקסט של Azure. בפועל, רוב היישומים האינטראקטיביים התומכים בדיבור משתמשים בשירות הדיבור באמצעות SDK ספציפי לשפה (תיכנות).
שימוש בערכת ה-SDK של דיבור לטקסט
בעוד הפרטים הספציפיים משתנים, בהתאם ל- SDK שבו נעשה שימוש (Python, C#, וכן הלאה); יש תבנית עקבית לשימוש ב – API של דיבור לטקסט:
- השתמש באובייקט SpeechConfig כדי לתמצת את המידע הדרוש להתחברות למשאב הדיבור שלך. באופן ספציפי, המיקום שלה ואת המפתח.
- לחלופין, השתמש ב – AudioConfig כדי להגדיר את מקור הקלט עבור השמע שיש לתמלל. כברירת מחדל, זהו מיקרופון המערכת המוגדר כברירת מחדל, אך באפשרותך גם לציין קובץ שמע.
- השתמש ב- SpeechConfig וב- AudioConfig כדי ליצור אובייקט SpeechRecognizer. אובייקט זה הוא לקוח proxy עבור ה- API של דיבור לטקסט.
- השתמש בשיטות של אובייקט SpeechRecognizer כדי לקרוא לפונקציות ה- API המשמשות כבסיס. לדוגמה, פעולת השירות RecognizeOnceAsync משתמשת בשירות הדיבור כדי לתמלל באופן אסינכרוני אמירה מדוברת אחת.
- עבד את התגובה משירות הדיבור. במקרה של פעולת השירות RecognizeOnceAsync, התוצאה היא אובייקט SpeechRecognitionResult הכולל את המאפיינים הבאים:
- משך
- אופסטInTicks
- מאפייני
- למה
- תוצאהאיד
- טקסט
אם הפעולה הצליחה, המאפיין סיבה כולל את הערך הממוספר RecognizedSpeech, והמאפיין טקסט מכיל את התמלול. ערכים אפשריים אחרים עבור תוצאה כוללים את NoMatch (המציין שהשמע נותח בהצלחה אך לא זוהה דיבור) או בוטל, המציין שאירעה שגיאה (במקרה זה, תוכל לבדוק את אוסף המאפיינים עבור המאפיין CancelReason כדי לקבוע מה השתבש.)
שימוש ב- API של טקסט לדיבור
בדומה לממשקי API של דיבור לטקסט, שירות הדיבור מציע שני ממשקי API של REST לסינתזת דיבור:
- ה- API של טקסט לדיבור , שהוא הדרך העיקרית לבצע סינתזת דיבור.
- ה- API של טקסט לדיבור Long Audio, שנועד לתמוך בפעולות אצווה הממירות כמויות גדולות של טקסט לשמע – לדוגמה, כדי ליצור ספר שמע מטקסט המקור.
באפשרותך לקבל מידע נוסף על ממשקי ה- API של REST בתיעוד ממשקי ה- API של REST של טקסט לדיבור של Azure. בפועל, רוב היישומים האינטראקטיביים התומכים בדיבור משתמשים בשירות הדיבור באמצעות SDK ספציפי לשפה (תיכנות).
שימוש בערכת ה- SDK של טקסט לדיבור
בדומה לזיהוי דיבור, בפועל רוב היישומים האינטראקטיביים התומכים בדיבור בנויים באמצעות ה- Speech SDK.
התבנית ליישום סינתזת דיבור דומה לזו של זיהוי דיבור:
- השתמש באובייקט SpeechConfig כדי לתמצת את המידע הדרוש להתחברות למשאב הדיבור שלך. באופן ספציפי, המיקום שלה ואת המפתח.
- לחלופין, השתמש ב – AudioConfig כדי להגדיר את התקן הפלט עבור הדיבור להיות מסונתז. כברירת מחדל, זהו רמקול המערכת המוגדר כברירת מחדל, אך באפשרותך גם לציין קובץ שמע, או על-ידי הגדרה מפורשת של ערך זה לערך Null, באפשרותך לעבד את אובייקט זרם השמע המוחזר ישירות.
- השתמש ב- SpeechConfig וב- AudioConfig כדי ליצור אובייקט SpeechSynthesizer. אובייקט זה הוא לקוח proxy עבור ה- API של טקסט לדיבור.
- השתמש בשיטות של אובייקט SpeechSynthesizer כדי לקרוא לפונקציות ה- API המשמשות כבסיס. לדוגמה, פעולת השירות SpeakTextAsync משתמשת בשירות הדיבור כדי להמיר טקסט לשמע מדובר.
- עבד את התגובה משירות הדיבור. במקרה של פעולת השירות SpeakTextAsync, התוצאה היא אובייקט SpeechSynthesisResult המכיל את המאפיינים הבאים:
- נתוני אודיו
- מאפייני
- למה
- תוצאהאיד
לאחר שהדיבור סונתז בהצלחה, המאפיין סיבה מוגדר כ SynthesizingAudioCompleted והמאפיין AudioData מכיל את זרם השמע (אשר, בהתאם ל- AudioConfig, ייתכן שנשלח באופן אוטומטי לרמקול או לקובץ).
בעת סינתזה של דיבור, באפשרותך להשתמש באובייקט SpeechConfig כדי להתאים אישית את השמע המוחזר על-ידי שירות הדיבור.
פורמט שמע
שירות הדיבור תומך בתבניות פלט מרובות עבור זרם השמע שנוצר על-ידי סינתזת דיבור. בהתאם לצרכים הספציפיים שלך, תוכל לבחור פורמט המבוסס על הנדרש:
- סוג קובץ שמע
- קצב דגימה
- עומק סיביות
הפורמטים הנתמכים מצוינים ב- SDK באמצעות ספירת SpeechSynthesisOutputFormat. לדוגמה, SpeechSynthesisOutputFormat.Riff24Khz16BitMonoPcm.
כדי לציין את תבנית הפלט הנדרשת, השתמש בפעולת השירות SetSpeechSynthesisOutputFormat של אובייקט SpeechConfig:
speechConfig.SetSpeechSynthesisOutputFormat(SpeechSynthesisOutputFormat.Riff24Khz16BitMonoPcm);
לקבלת רשימה מלאה של תבניות נתמכות וערכי הספירה שלהן, עיין בתיעוד של Speech SDK.
קולות
שירות הדיבור מספק קולות מרובים שבהם באפשרותך להשתמש כדי להתאים אישית את היישומים התומכים בדיבור שלך. ישנם שני סוגים של קול שניתן להשתמש בהם:
- קולות סטנדרטיים – קולות סינתטיים שנוצרו מדגימות שמע.
- קולות עצביים – קולות נשמעים טבעיים יותר הנוצרים באמצעות רשתות עצביות עמוקות.
קולות מזוהים על ידי שמות המציינים אזור ושם של אדם – לדוגמה en-GB-George.
כדי לציין קול לסינתזת דיבור ב- SpeechConfig, הגדר את המאפיין SpeechSynthesisVoiceName לקול שבו ברצונך להשתמש:
speechConfig.SpeechSynthesisVoiceName = "en-GB-George";
שימוש בשפת סימון של סינתזת דיבור
בעוד שערכת ה- SDK של הדיבור מאפשרת לך לשלוח טקסט רגיל לסינתזה לדיבור (לדוגמה, באמצעות פעולת השירות SpeakTextAsync, השירות תומך גם בתחביר מבוסס XML לתיאור מאפייני הדיבור שברצונך ליצור. תחביר זה של שפת סימון סינתזת דיבור (SSML) מציע שליטה רבה יותר על האופן שבו הפלט המדובר נשמע, ומאפשר לך:
- ציין סגנון דיבור, כגון "נרגש" או "עליז" בעת שימוש בקול עצבי.
- הוסף הפסקות או שתיקה.
- ציין פונמות (הגייה פונטית), לדוגמה כדי לבטא את הטקסט "SQL" כ-"sequel".
- התאם את הפרוזודיה של הקול (המשפיעה על גובה הצליל, הגוון וקצב הדיבור).
- השתמש בכללי "say-as" נפוצים, לדוגמה, כדי לציין שמחרוזת נתונה צריכה להיות מבוטאת כתאריך, שעה, מספר טלפון או צורה אחרת.
- הוסף דיבור או שמע מוקלטים, לדוגמה כדי לכלול הודעה מוקלטת רגילה או לדמות רעשי רקע.
לדוגמה, שקול את ה- SSML הבא:
<Speak Version="1.0" xmlns ="https://www.w3.org/2001/10/synthesis" xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang="en-US"> <Sound name="en-US-AriaNeural"> <mstts:express-as-style ="cheerful"> I say tomatoes </mstts:express-as> </voice> <Sound name="en-US-GuyNeural"> I say <phoneme alphabet="sapi"ph="t ao m ae t ow"> tomato </phoneme>. <Break power = "weak"/>Let's read the whole thing! </voice> </speak>
SSML זה מציין דיאלוג מדובר בין שני קולות עצביים שונים, כך:
- אריאנה (בעליזות): "אני אומרת עגבנייה:
- גיא: "אני אומר עגבנייה (מבוטא טום-אה-בוהן) … בואו נפסיק את כל העניין!"
כדי לשלוח תיאור SSML לשירות הדיבור, באפשרותך להשתמש בפעולת השירות SpeakSsmlAsync באופן הבא:
speechSynthesizer.SpeakSsmlAsync(ssml_string);
לקבלת מידע נוסף אודות SSML, עיין בתיעוד של Speech SDK.
תרגום דיבור באמצעות שירות הדיבור
תרגום דיבור מתבסס על זיהוי דיבור על-ידי זיהוי ותמלול קלט מדובר בשפה מסוימת , והחזרת תרגומים של התמלול בשפה אחת או יותר.
- קצאה של משאבי Azure לתרגום דיבור.
- תרגום טקסט מדיבור.
- סינתזה של תרגומים מדוברים.
היחידות במודול כוללות מידע מושגי חשוב על שירות הדיבור וכיצד להשתמש ב- API שלו באמצעות אחת מערכות פיתוח התוכנה (SDK) הנתמכות, ולאחר מכן תוכל לנסות את שירות הדיבור בעצמך בתרגיל מעשי. כדי להשלים את התרגיל המעשי, תזדקק למנוי של Microsoft Azure. אם עדיין אין לך תוכנית כזו, תוכל להירשם לגירסת ניסיון ללא תשלום ב-https://azure.com/free
הקצאת משאב Azure לתרגום דיבור
שירות הדיבור מספק שירותי תרגום דיבור חזקים המבוססים על למידת מכונה ובינה מלאכותית, ומאפשר למפתחים להוסיף תרגומי דיבור מקצה לקצה, בזמן אמת, ליישומים או לשירותים שלהם.
לפני שתוכל להשתמש בשירות הדיבור, עליך ליצור משאב דיבור במנוי Azure שלך. באפשרותך להשתמש במשאב דיבור ייעודי או במשאב שירותים קוגניטיביים מרובה שירותים .
לאחר יצירת משאב Azure, תזדקק למידע הבא כדי להשתמש בו מיישום לקוח באמצעות אחת מערכות ה- SDK הנתמכות:
- המיקום שבו המשאב נפרס (לדוגמה, eastus)
- אחד המפתחות שהוקצו למשאב שלך.
באפשרותך להציג ערכים אלה בדף מפתחות ונקודות קצה עבור המשאב שלך בפורטל Azure.
תרגום דיבור לטקסט
התבנית לתרגום דיבור באמצעות ה- Speech SDK דומה לזיהוי דיבור, עם תוספת של מידע אודות שפות המקור ושפת היעד לתרגום:
השתמש באובייקט SpeechConfig כדי לתמצת את המידע הדרוש להתחברות למשאב הדיבור שלך. באופן ספציפי, המיקום שלה ואת המפתח.
- השתמש באובייקט SpeechTranslationConfig כדי לציין את שפת זיהוי הדיבור (השפה שבה דיבור הקלט) ואת שפות היעד שאליהן יש לתרגם אותו.
- לחלופין, השתמש ב – AudioConfig כדי להגדיר את מקור הקלט עבור השמע שיש לתמלל. כברירת מחדל, זהו מיקרופון המערכת המוגדר כברירת מחדל, אך באפשרותך גם לציין קובץ שמע.
- השתמש ב- SpeechConfig, SpeechTranslationConfig ו- AudioConfig כדי ליצור אובייקט TranslationRecognizer. אובייקט זה הוא לקוח proxy עבור ה- API של תרגום שירות דיבור.
- השתמש בשיטות של אובייקט TranslationRecognizer כדי לקרוא לפונקציות ה- API המשמשות כבסיס. לדוגמה, פעולת השירות RecognizeOnceAsync משתמשת בשירות הדיבור כדי לתרגם באופן אסינכרוני אמירה מדוברת אחת.
- עבד את התגובה משירות הדיבור. במקרה של פעולת השירות RecognizeOnceAsync, התוצאה היא אובייקט SpeechRecognitionResult הכולל את המאפיינים הבאים:
- משך
- אופסטInTicks
- מאפייני
- למה
- תוצאהאיד
- טקסט
- תרגומים
אם הפעולה הצליחה, המאפיין סיבה כולל את הערך הממוספר RecognizedSpeech, המאפיין טקסט מכיל את התעתיק בשפת המקור, והמאפיין תרגומים מכיל מילון של התרגומים (באמצעות קוד שפת ISO בן שני תווים, כגון "en" עבור אנגלית, כמפתח).
סינתזה של תרגומים
ה- TranslationRecognizer מחזיר תמלולים מתורגמים של קלט מדובר – ובעצם מתרגם דיבור קולי לטקסט.
באפשרותך גם לסנתז את התרגום כדיבור כדי ליצור פתרונות תרגום דיבור לדיבור. ישנן שתי דרכים להשיג זאת.
סינתזה מבוססת אירועים
כאשר ברצונך לבצע תרגום 1:1 (תרגום משפת מקור אחת לשפת יעד אחת), באפשרותך להשתמש בסינתזה מבוססת אירועים כדי ללכוד את התרגום כזרם שמע. לשם כך, עליך:
- ציין את הקול הרצוי עבור הדיבור המתורגם ב – TranslationConfig.
- צור מטפל באירועים עבור אירוע הסינתזה של אובייקט TranslationRecognizer.
- במטפל באירועים, השתמש בשיטה GetAudio של הפרמטר Result כדי לאחזר את זרם הבתים של שמע מתורגם.
הקוד הספציפי המשמש ליישום מטפל באירועים משתנה בהתאם לשפת התיכנות שבה אתה משתמש. ראה את הדוגמאות C# ו – Python בתיעוד של Speech SDK.
סינתזה ידנית
סינתזה ידנית היא גישה חלופית לסינתזה מבוססת אירועים שאינה דורשת ממך ליישם מטפל באירועים. ניתן להשתמש בסינתזה ידנית כדי ליצור תרגומי שמע עבור שפת יעד אחת או יותר.
סינתזה ידנית של תרגומים היא למעשה רק שילוב של שתי פעולות נפרדות שבהן אתה:
- השתמש ב – TranslationRecognizer כדי לתרגם קלט מדובר לתמלולי טקסט בשפת יעד אחת או יותר.
- חזור על כך באמצעות מילון התרגומים כתוצאה מפעולת התרגום, תוך שימוש ב– SpeechSynthesizer כדי לסנתז זרם שמע עבור כל שפה.




