





הסיבה שאנו מודעים יותר לשמה של ה Vlookup , ופחות ל- Hlookup – היא שרוב הנתונים נכתבים בצורה אנכית, כלומר, רשימה של נתונים על פני שורות רבות ולא על פני עמודות רבות וזהו כל ההבדל בין שתי הנוסחאות:
V = אנכי: vertical
H = אופקי: horizontal
אנו משתמשים בנוסחה זו, כשאנו עובדים על בסיס נתונים-טבלה אחת, ורוצים למצוא נתונים שנמצאים בטבלה אחרת. נדגים ונסביר:
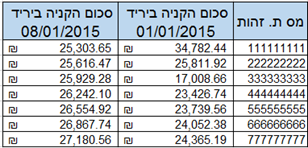
לפנינו טבלה בה נתונים על המכירות ביריד. בעמודה הימנית – מספרי הזהות של הקונים.
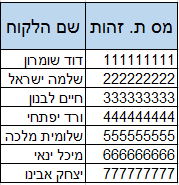
אנו רוצים לדעת מיהם אותם הקונים, וידוע לנו שבקובץ אחר ישנה טבלה בה מספר הזהות מופיע ולידו שם הקונה, הנה, זאת שלהלן:
במקרה זה נרצה שהאקסל יזהה את מספרי הזהות בטבלה המקורית שלי, ומכיוון שמספר זהות הוא ייחודי לכל אחד – ניתן לקשר אליו את שם הקונה.
כפי שכבר אמרנו, רוב הטבלאות – נכתבות באופן אנכי. לכן נבצע את פונקציית – Vlookup – שפועלת על נתונים אנכיים.
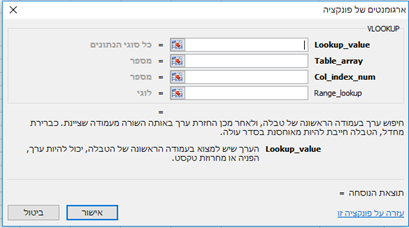
התחביר של הנוסחה הוא פשוט, ונציג את 4 ארגומנטים אותם נצטרך למלא:
- Lookup value
תפקידו לחפש את הערך אותו אני רוצה למצוא בטבלה – במקרה זה – מספר הזהות.
- Table array
בארגומנט זה נפנה אל הטבלה או הטווח ממנה אנו רוצים לאחזר (למצוא) את הנתונים – במקרה זה – מהטבלה השנייה.
- Col index num
בארגומנט זה נכתוב את מספר העמודה בטבלה ממנה אחזרנו, ובה נמצאים הנתונים שאנו מחפשים – במקרה זה – אנו מחפשים את שם הקונה, ונראה שהוא נמצא בעמודה השנייה (בטבלה המאוחזרת – השנייה) – ולכן נכתוב: 2
- Range lookup
ארגומנט רביעי איננו מודגש ולכן במקרה של התאמה משוערת – נוכל להשאירו ריק.
במקרה זה – אנו רוצים התאמה מדויקת – בדיוק את שם הקונה – ולכן נקליד: False או 0/
ולכן התחביר המלא של הנוסחה יהיה: VLOOKUP(G4,$D$3:$E$10,2,FALSE) =
הערה חשובה: אם נסתכל שנית על ההסבר של Lookup value – נראה שרשום: "הערך שיש למצוא בעמודה הראשונה של הטבלה.." – חשוב להבין שנוסחה זו עובדת רק אם מספר הזהות, בטבלה ממנה אנו רוצים לקחת את שם הקונה, מופיע בעמודה הימנית ביותר – אם שם הלקוח יהיה מימין למספר הזהות – אי אפשר יהיה להשתמש בנוסחת Vlookup, ועלינו יהיה לחפש נוסחת חיפוש – שליפה – והשמה אחרת.
הצגנו את הארגומנט הרביעי כארגומנט – התאמה מדויקת.
לכאורה, ברור שנרצה התאמה מדויקת – למה לנו לחפש התאמה משוערת?
ניתן כעת דוגמה להתאמה משוערת ונבין:
כשאנו נעבוד עם גיליון ציונים – וכל תלמיד יקבל ציון אחר – יתכן ונרצה להגדיר נוסחה שתזהה את הציון של התלמיד – אם הוא קיבל 60 – עבר ; אם הוא קיבל 70 – סביר ; 80 – בהצלחה.. וכו' ע"פ הטבלה מטה.
| עבר |
| סביר |
| בהצלחה |
| בהצטיינות |
| בהצטיינות יתרה |
במקרה זה נשתמש בהתאמה משוערת- סביר להניח שלא כל התלמידים יקבלו במדויק 80, 90, 100, 60 וכו'
ולכן, כשתלמיד יקבל 77 – נרצה שהאקסל יחזיר תשובה – סביר, ואם יקבל התלמיד 82 – נרצה שהאקסל יחזיר תשובה – בהצלחה, וכך הלאה לכן:
בשלב הראשון נבנה טבלת עזר – חשוב ביותר שתהיה מסודרת בסדר עולה – כפי זאת שלהלן:
| ציונים | תיאור |
| 0 | נכשל |
| 60 | עבר |
| 70 | סביר |
| 80 | בהצלחה |
| 90 | בהצטיינות |
| 100 | בהצטיינות יתרה |
בשלב השני בארגומנט הרביעי Range lookup – שקודם רשמנו בו התאמה מדויקת – כעת נקליד בו 1 או TRUE או שנשאיר אותו מושמט – כלומר לא נכתוב בו כלום.




